
32
zobrazenie

Batyanov Denis o právach autora hodnotení vysvetľuje v tomto príspevku o tom, ako nájsť dáta v jednom Excel a extrahovať do druhého, a zisťuje, všetky tajomstvá vertikálne funkcia sledovania.
Pri práci v vynikať Veľmi často je potreba nájsť dáta v tabuľke a odstrániť ich na druhú. Ak si neviete, ako to urobiť, potom som si prečítal článok, budete nielen učiť, ale aj zistiť, za akých podmienok bude môcť vytlačiť maximálny výkon systému. Považované za najviac vysoko účinné metódy, ktoré by mali byť použité v spojení s funkciou CDF.
Dokonca aj keď máte rokoch používania funkcie CDF, s veľkou pravdepodobnosťou tento článok bude užitočné pre vás a nenechá ľahostajným. Ja, napríklad, ako IT špecialista, a potom líder v oblasti IT, ktorý sa používa funkcia VLOOKUP 15 rokov, ale Vysporiadať sa všetkými nuansami sa stalo práve, keď som na profesionálnej báze som začal učiť ľudia Excel.
CDF - skratka vvertikálne, atď.inšpekcie. Podobne VLOOKUP - vertikálne vyhľadávanie. Samotný názov funkcie naznačuje nám, že hľadá riadky tabuľky (vertikálne - triediace linky a upevnenie osi), a nie v stĺpci (horizontálny - zoradením stĺpcov a upevnenie line). Je potrebné poznamenať, že CDF má sestru - Škaredé káčatko, ktoré sa nikdy nestane labuť - je závislá na PGR (VVYHLEDAT). PGR, na rozdiel od CDF, vytvára horizontálne vyhľadávanie, ale koncept Excel (a naozaj konceptu organizovať dáta) znamená, že vaše tabuľky majú malý počet stĺpcov a mnoho ďalších linky. To je dôvod, prečo hľadanie reťazca, sme viac než stĺpcov treba mnohokrát. ak sa vám
vynikať Až príliš často používajú VVYHLEDAT, to je celkom pravdepodobné, že tam je niečo, čo nechcete pochopiť, v tomto živote.VLOOKUP má štyri parametre:
PPS = (
Stavím sa, že mnohí z tých, ktorí poznajú funkciu CDF ako peeling, prečítajte si popis štvrtý parameter môže cítiť nepríjemne, pretože používa ho vidieť v mierne odlišným spôsobom: obvykle je tu reč o presnom súlade s hľadaním (nepravda alebo 0), alebo o rovnakom zornom poli (TRUE alebo 1).
Teraz je potrebné, aby sprísnila a prečítať ďalší odsek niekoľkokrát, až sa dostanete pocit pre zmysle toho, čo bolo povedané, až do konca. Tam je každé slovo dôležité. Príklady pomôže pochopiť.
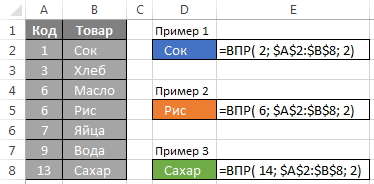
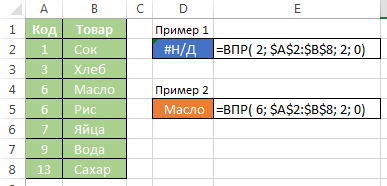


Ak sa zistí, že hodnota v prvom stĺpci matice niekoľkokrát, bude vzorec zvoliť prvý riadok pre neskoršie použitie.
Ste dosiahli vrchol v mieste článku. Mohlo by sa zdať, dobre, v čom je rozdiel, či by som poukázať na to ako posledný parameter nula alebo jedna? V podstate celý bod, samozrejme nula, pretože to je celkom praktické: nie je potrebné sa obávať triedenie prvý stĺpec matice, jeden môže vidieť, našiel hodnotu, alebo nie. Ale ak máte zoznam niekoľkých tisíc vzorcov CDF (VLOOKUP), všimnete si, že typ CDF beží II pomaly. To je zvyčajne všetko začalo premýšľať:
A len málo ľudí si myslí, že akonáhle začnete CDF typu I a zabezpečiť nejaký spôsob, ako triediť prvý stĺpec ako rýchlosť operácia CDF zvýši 57 krát. Píšem slova - za päťdesiat sedemkrát! V 57% a 5700%. Táto skutočnosť Overil som si celkom spoľahlivo.
Tajomstvo týchto rýchlych práca spočíva v tom, že môžete použiť na triedenom poli je nesmierne efektívna vyhľadávací algoritmus, ktorý je známy ako metóda binárne vyhľadávanie (bisekce, dichotómia). Tak nejako som CDF používa ho, a typ CDF II usiluje bez optimalizácie všeobecne. To isté platí pre zápasu (Match), ktorý obsahuje rovnaký parameter, a tiež na funkciu SLEDOVANIE (LOOKUP), ktorý možno použiť iba u triedených polí a aktivovaný v Exceli pre kompatibilitu s Lotus 1-2-3.
Nevýhody CDF sú zrejmé: najprv sa snažia iba prvý stĺpec tohto poľa, a za druhé, práve napravo od tohto stĺpca. A ako viete, môže sa stať, že stĺpec, ktorý obsahuje potrebné informácie v ľavej časti kolóny, v ktorej sa snažíme. Nemajú tento nedostatok už bolo spomenuté veľa vzorcov INDEX + MATCH (INDEX + MATCH), ktorý sa najviac flexibilné riešenie pre extrakciu dát z tabuľky v porovnaní s CDF (VLOOKUP) robí.
Klasický obrázok o rozsahu vyhľadávanie - problém stanovenie veľkosti zliav poriadku.

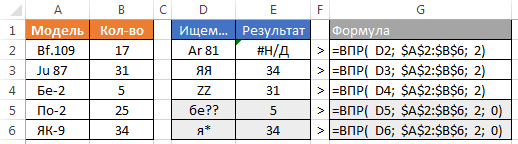
Samozrejme, že CDF usiluje nielen čísla, ale aj text. Treba mať na pamäti, že veľké a malé písmená formuly nerozlišuje. Ak použijete zástupné znaky, je možné usporiadať fuzzy vyhľadávania. Existujú dva zástupné znaky "?" - nahrádza ľubovoľný znak v textovom reťazci "*" - nahrádza ľubovoľný počet akýchkoľvek znakov.
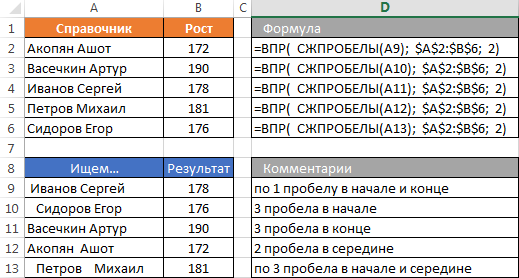
Často vyvstáva otázka, ako vyriešiť problém dodatočných priestorov v hľadaní. Ak je v tabuľke look-up je stále možné ich čistiť, prvý parameter vzorca CDF nie je vždy závisieť na vás. Z tohto dôvodu, ak je riziko upchatia bunkám viac priestoru je k dispozícii, je možné použiť funkciu TRIM (TRIM) za účelom čistenia.
V prípade, že prvý parameter funkcie CDF sa týka bunky, ktorá obsahuje číslo, ale ktorý je uložený v bunky ako text a prvý stĺpec matice obsahuje čísla v správnom formáte, bude vyhľadávanie mať neúspešné. Obrátená situácia. Problém je ľahko vyriešiť parametrom prevodu 1 do požadovaného formátu:
PPS = (- D7; Produkty $ A $ 2: $ C $ 5;! 3; 0) - ak D7 obsahuje text a tabuľky - čísla;
= CDF (D7 & «»); Produkty $ A $ 2: $ C $ 5;! 3; 0) - a naopak.
Mimochodom, preložiť text v rade môže byť niekoľko spôsobov, vyberte:
Preklad textu vyrába kopuláciou s prázdny reťazec, ktorý spôsobuje Excel previesť dátový typ.
To je veľmi výhodné čo do činenia s funkciou IFERROR (IFERROR).
Napríklad: = IFERROR (CDF (D7; Produkty $ A $ 2: $ C $ 5;! 3; 0); «»).
V prípade, že CDF vráti kód chyby # N / A, potom sa zachytia IFERROR náhradu a parameter 2 (v tomto prípade, prázdny reťazec), a Ak nedošlo k žiadnej chybe, bude táto funkcia predstierať, že to nie je vôbec, ale len CDF, obnovené k normálu vyplývať.
Často prehliadaná referenciu zoskupenie je vytvorené absolútna, a keď sa tiahne celý rad "pláva". Uvedomte si, že namiesto toho, A2: C5 by mali byť použité $ $ 2: $ C $ 5.
Dobrý nápad je umiestniť referenčné polia na samostatnom liste v zošite. To nedostane pod nohami, a bude mať uložené.
Ešte dobrý nápad vyhlásením poľa ako pomenované oblasti.
Mnoho používateľov sa používajú pri určovaní štruktúry typu pole A: C, čo ukazuje stĺpce úplne. Tento prístup má právo na existenciu, pretože ste ušetrení nutnosti udržanie prehľadu o tom, že vaše pole obsahuje všetky nitky. Ak máte pridať riadok na kus pôvodného poľa, rozsah špecifikovaný ako A: C, nebudú musieť prispôsobiť. Samozrejme, táto syntax spôsobí Excel stráviť trochu viac práce, než s presným údajom o rozsahu, ale dáta réžia je zanedbateľný. Reč je o stotín sekundy.
No, na pokraji génia - k problému v podobe matice smart stolík.
V prípade, že tabuľka, do ktorého extrahovať dáta pomocou CDF, má rovnakú štruktúru ako tabuľky look-up, ale len obsahuje minimálny počet riadkov v WRT domény môžu byť použité stĺpcové funkcie () pre automatické výpočet počtu nahraditeľných stĺpy. V tomto prípade všetky CDF-formula bude rovnaká (očistené o prvý parameter, ktorý automaticky zmení)! Všimnite si, že prvý parameter je absolútna súradnice kolóny.

Ak je potreba pozrieť sa na viac ako jednom stĺpci naraz, je nutné, aby sa zložený kľúč pre vyhľadávanie. V prípade, že vrátená hodnota nie je Text (ako je tu v prípade poľa "kód"), a numerický, pre Toto prišlo do vhodného vzorca SUMIFS (SUMIFS) a integrálne stĺpci kľúč by nemali byť povinné vôbec.

Toto je môj prvý článok na Layfhakera. Ak sa vám to páčilo, a potom vás pozývam na návštevu môj webA rád čítal vaše komentáre o tajomstve pomocou funkcie VLOOKUP a podobne. Ďakujem. :)